Los administradores de sistemas distribuidos se ocupan de monitorear continuamente al sistema y se deben de asegurar de su disponibilidad. Para una buena administración, se debe de poder identificar las áreas que están teniendo problemas así como de la rápida recuperación de fallas que se puedan presentar. La información que se obtiene mediante el monitoreo sirve a los administradores para anticipar situaciones críticas. La prevención de estas situaciones ayuda a que los problemas no crezcan para que no afecten a los usuarios del sistema.
5.1.1 Instalación de Sistemas Operativos Distribuidos
—El instalar un sistema operativo no es solo instalar un CD y ejecutarlo, ya que debe configurarse para blindarlo de amenazas y ofrecer mayor seguridad.
Una vez instalado el sistema operativo se deben realizar las siguientes acciones:
1. Verificar que el firewall esté habilitado y habilitarlo en caso contrario.
2. Actualizar a las últimas versiones del producto.
3. Verificar las actualizaciones automáticas
4. Habilitar la protección antivirus.
5. Crear un usuario con permisos no-administrativos y dejar el usuario "Administrador" sólo para tareas de instalación y mantenimiento
6. Deshabilitar algunos servicios del Sistema operativo para usuarios con acceso restringido.
Control Sod
—El Control de Sistemas e Informática, consiste en examinar los recursos, las operaciones, los beneficios y los gastos de las producciones, de los Organismos sujetos a control, con la finalidad de evaluar la eficacia y eficiencia Administrativa Técnica de los Organismos, en concordancia con los principios, normas, técnicas y procedimientos normalmente aceptados. Asimismo de los Sistemas adoptados por la Organización para su dinámica de Gestión en salvaguarda de los Recursos del Estado.
5.2 Estándares de administración de SOD
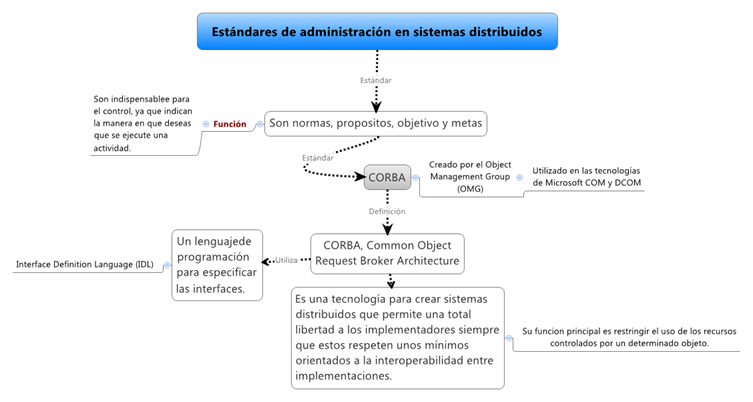
Los estándares son aquellas normas usuales, los propósitos, los objetivos, a alcanzar, las metas a alcanzar y aquellos índices que integran los planes, y todo dato o cifra que pueda emplearse como medida para cumplirlas, son considerados como estándares.
Estas medidas son indispensables para el control, ya que indican la manera en que deseas que se ejecute una actividad. En la práctica, son los objetivos declarados y definidos de la organización y por esa razón los estándares deben abarcar las funciones básicas y áreas clave de los resultados logrados.
Un estándar muy utilizado en los sistemas distribuidos es el CORBA, en el cual nos basaremos para explicar este tema.
CORBA es el estándar para la creación de sistemas distribuidos creado por el Object Management Group (OMG). Pensado para ser independiente del lenguaje, rápidamente aparecieron implementaciones en las que se podía usar casi cualquier lenguaje.
5.3 Tendencias de Investigación Sistemas Distribuidos
Una tendencia reciente en los sistemas de computador es distribuir el cómputo entre varios procesadores. En contraste con los sistemas fuertemente acoplados, los procesos no comparten ni la memoria ni el reloj. Los procesadores se comunican entre sí a través de diversas líneas de comunicación, como buses de alta velocidad o líneas telefónicas.
Los procesadores de estos sistemas pueden tener diferentes tamaños y funciones que pueden incluir microprocesadores pequeños, estaciones de trabajo, minicomputadoras y sistemas de computador de propósito general o distribuido. Tales procesadores pueden recibir varios nombres como: sitios, nodos, etc., dependiendo del contexto en que se mencionan.
5.4 Sistemas Distribuidos y la Sociedad
El comportamiento de los usuarios (sociedad) ha variado los últimos años, en los que muchos de ellos ya están introduciendo a este nuevo mundo de tecnología.
El impacto en los sistemas distribuidos dentro de la sociedad ha ayudado a facilitar el trabajo al hombre. Ya que existen medios e interfaces que ayudan a un usuario a interactuar por medio de computadora para realizar infinidades de tareas que anteriormente eran difíciles.Con el uso de ha sido posible el uso de aplicaciones comerciales, aplicaciones de red de área extensa y aplicaciones multimedia.
Esto ha favorecido también al crecimiento económico de una organización o empresa ya sea pública o privada.
Los sistemas de Memoria Compartida Distribuida (MCD), son sistemas que, mediante software, emulan semántica de memoria compartida sobre hardware que ofrece soporte solo para comunicación mediante paso de mensajes. Este modelo permite utilizar una red de estaciones de trabajo de bajo costo como una maquina paralela con grandes capacidades de procesamiento y amplia escalabilidad, siendo a la vez fácil de programar.
El objetivo principal de estos sistemas es permitir que un multicomputador pueda ejecutar programas escritos para un multiprocesador con memoria compartida
Cada uno de los nodos en un sistema de MCD aporta una parte de su memoria local para construir un espacio global de direcciones virtuales que será empleado por los procesos paralelos que se ejecuten en el sistema. El software de MCD se encarga de interceptar las referencias a memoria que hacen los procesos, y satisfacerlas, ya sea local o remotamente.
4.1 Configuraciones de memoria compartida distribuida.
COMPUTACIÓN PARALELA
Un computador paralelo es un conjunto de procesadores capaces de cooperar en la solución de un problema. El problema se divide en partes. Cada parte se compone de un conjunto de instrucciones. Las instrucciones de cada parte se ejecutan simultáneamente en diferentes CPUs. Técnicas computacionales que descomponen un problema en sus tareas y pistas que pueden ser computadas en diferentes máquinas o elementos de proceso al mismo tiempo.
Por qué utilizar computación paralela?
Reducir el tiempo de procesamiento
Resolver problemas de gran embergadura.
Proveer concurrencia.
Utilizar recursos remotos de cómputo cuando los locales son escasos.
Reducción de costos usando múltiples recursos "baratos" en lugar de costosas supercomputadoras.
Ampliar los límites de memoria para resolver problemas grandes.
El mayor problema de la computación paralela radica en la complejidad de sincronizar unas tareas con otras, ya sea mediante secciones críticas, semáforos o paso de mensajes, para garantizar la exclusión mutua en las zonas del código en las que sea necesario.
La computación paralela está penetrando en todos los niveles de la computación, desde computadoras masivamente paralelas usados en las ciencias de larga escala computacional, hasta servidores múltiples procesadores que soportan procesamiento de transacciones. Los principales problemas originados en cada uno de las áreas básicas de la informática (por ejemplo, algoritmos, sistemas, lenguajes, arquitecturas, etc.) se vuelven aún más complejos dentro del contexto de computación paralela.
DE CIRCUITOS, BASADOS EN BUS, ANILLO O CON CONMUTADOR
Existen varias formas de implantar físicamente memoria compartida distribuida, a continuación se describen cada una de ellas.
Memoria basada en circuitos: Existe una única área de memoria y cada micro tiene su propio bus de datos y direcciones (en caso de no tenerlo se vuelve un esquema centralizado)
MCD basada en bus: En este esquema los micros comparten un bus de datos y direcciones por lo que es más barato de implementar, se necesita tener una memoria caché grande y sumamente rápida.
Multiprocesadores tipo bus.
Conexión entre CPU y memoria se hace a través de cables paralelos:
o Algunos transmiten las direcciones y datos que el CPU quiere leer o escribir
o Otros envían o reciben datos
o El resto para controlar las transferencias.
Dicha colección de cables se conoce con el nombre de bus.
Buses pueden ser parte del chip, pero en la mayoría de los sistemas los buses son externos y son usados para conectar circuitos impresos.
Una forma simple de construir multiprocesadores es conectarlos en un bus con más de un CPU.
MCD basada en anillos: Es más tolerante a fallos, no hay coordinador central y se privilegia el uso de la memoria más cercana.
Multiprocesadores basados en anillo.
Ejemplo Memnet: un espacio de direcciones se divide en una parte privada y otra compartida.
La parte privada:
o se divide en regiones cada máquina cuenta con memoria para su pila, datos y códigos no compartidos.
Parte compartida:
o común a todas las máquinas y se guarda de forma consistente mediante un protocolo de hardware parecido a los de bus se divide en bloques de 32 bytes, (unidad transferencia)
MCD basada en conmutador: Varios micros se conectan entre sí en forma de bus formando un grupo, los grupos están interconectados entre sí a través de un conmutador. Cuando se realiza una operación de memoria se intenta realizar dentro del grupo, de lo contrario pasa al conmutador para que lo redirecciones a otro grupo.
Multiprocesadores con conmutador.
En anillo o bus, el hecho de añadir un CPU satura el ancho de banda del bus o anillo
Dos métodos para solucionar el problema:
o 1. Reducir la cantidad de comunicación
o 2. Incrementar la capacidad de comunicación
Una forma de reducir la cantidad de comunicación es el ocultamiento trabajo adicional en esta área:
o mejorar protocolo de ocultamiento
o optimizar el tamaño del bloque
o incrementar la localidad de las referencias a memoria.
Sin embargo siempre se querrá añadir más CPUs y no habrá más ancho de banda en el bus.
4.2 Modelos de consistencia.
Un modelo de consistencia de memoria especifica las garantías de consistencia que un sistema MCD realiza sobre los valores que los procesos leen desde los objetos, dado que en realidad acceden sobre una réplica de cada objeto y que múltiples procesos pueden actualizar los objetos.
La duplicidad de los bloques compartidos aumenta el rendimiento, pero produce un problema de consistencia entre las diferentes copias de la página en caso de una escritura.
Si cada escritura es necesario actualizar todas las copias el envió de las paginas por red provoca que el tiempo de espera aumente demasiado convirtiendo el método en impracticable.
CARACTERISTICAS DE CONSISTENCIA
• Mantener consistencia no es algo simple.
• Un simple acceso a memoria puede requerir un gran número de paquetes a ser enviados.
ESTRICTA, CASUAL, SECUENCIAL, DEBIL, DE LIBERACION Y DE ENTRADA
CONSISTENCIA ESTRICTA: El modelo de consistencia más restrictivo es llamado consistencia estricta y es definido por la siguiente condición cualquier lectura sobre un ítem de dato X retorna un valor correspondiente con la más reciente escritura sobre X.
CONSISTENCIA CASUAL: Es un debilitamiento de la consistencia secuencial. Se hace una diferenciación entre eventos que están potencialmente relacionados en forma casual y aquellos que no.
La condición a cumplir para que unos datos sean casualmente consistentes es:
Escrituras que están potencialmente relacionados en forma casual deben ser vistas por todos los procesos en el mismo orden.
Esta secuencia es permitida con un almacenamiento casualmente consistente o con un almacenamiento consistente en forma estricta.
La condición a cumplir para que unos datos sean causalmente consistentes es:Escrituras que están potencialmente relacionadas en forma causal deben ser vistas por todos los procesos en el mismo orden.
Escrituras concurrentes pueden ser vistas en un orden diferente sobre diferentes máquinas.
Esta secuencia es permitida con un almacenamiento causalmente consistente, pero no con un almacenamiento secuencialmente consistente o con un almacenamiento consistente en forma estricta.
CONSISTENCIA SECUENCIAL: La consistencia secuencial es una forma ligeramente más débil de la consistencia estricta. Satisface la siguiente condición:
El resultado de una ejecución es el mismo si las operaciones (lectura y escritura) de todos los procesos sobre el dato fueron ejecutadas en algún orden secuencial y las operaciones de cada proceso individual aparecen en esta operaciones de cada proceso individual aparecen en esta secuencia en el orden especificado por su programa
a) Un dato almacenado secuencialmente consistente.
b) Un dato almacenado que no es secuencialmente consistente.
CONSISTENCIA DÉBIL: Los accesos a variables de sincronización asociadas con los datos almacenados son secuencialmente consistentes.
Propiedades:
No se permite operación sobre una variable de sincronización hasta que todas las escrituras previas de hayan completado. No se permiten operaciones de escritura o lectura sobre ítems de datos hasta que no se hayan completado operaciones previas sobre variables de sincronización.
CONSISTENCIA LIBERACIÓN (RELEASE): El modelo de consistencia release, RC, se basa en el supuesto de que los accesos a variables compartidas se protegen en secciones críticas empleando primitivas de sincronización, como por ejemplo locks. En tal caso, todo acceso esta precedido por una operación adquiere y seguido por una operación release. Es responsabilidad del programador que esta propiedad se cumpla en todos los programas.
Puesto que ningún otro proceso, ni local ni remoto, puede acceder a las variables que han sido modificadas mientras se encuentren protegidas en la sección critica, la actualización de cualquier modificación puede postergarse hasta el momento en que se lleva a cabo la operación reléase.
Propagación de Actualizaciones bajo RC y LRC de código sin proteger. En consecuencia obtuvo un valor inconsistente para la variable leída.
4.3 MCD en base de páginas.
Cada CPU cuenta con su propia memoria y no pueden referenciar memoria remota directamente.
Cuando dirección CPU se encuentra en una página que reside en una máquina remota:
Se notifica al sistema operativo
Sistema solicita dicha página con un mensaje.
Tanto ubicación como acceso son realizados a nivel software.
Ejemplos: IVY y Mirage
El esquema de MCD propone un espacio de direcciones de memoria virtual que integre la memoria de todas las computadoras del sistema, y su uso mediante paginación. Las páginas quedan restringidas a estar necesariamente en un único ordenador. Cuando un programa intenta acceder a una posición virtual de memoria, se comprueba si esa página se encuentra de forma local. Si no se encuentra, se provoca un fallo de página, y el sistema operativo solicita la página al resto de computadoras.
El sistema funciona de forma análoga al sistema de memoria virtual tradicional, pero en este caso los fallos de página se propagan al resto de ordenadores, hasta que la petición llega al ordenador que tiene la página virtual solicitada en su memoria local. A primera vista este sistema parece más eficiente que el acceso a la memoria virtual en disco, pero en la realidad ha mostrado ser un sistema demasiado lento en ciertas aplicaciones, ya que provoca un tráfico de páginas excesivo.
Una mejora dirigida a mejorar el rendimiento sugiere dividir el espacio de direcciones en una zona local y privada y una zona de memoria compartida, que se usará únicamente por procesos que necesiten compartir datos. Esta abstracción se acerca a la idea de programación mediante la declaración explícita de datos públicos y privados, y minimiza el envío de información, ya que sólo se enviarán los datos que realmente vayan a compartirse.
DISEÑO REPLICA GRANULARIDAD CONSISTENCIA
Hay dos razones principales para la replicación de datos:
Confiabilidad
Continuidad de trabajo ante caída de la réplica, mayor cantidad de copias mejor protección contra la corrupción de datos.
Rendimiento
El SD escala en número
Escala en área geográfica (disminuye el tiempo de acceso al dato) Consulta simultánea de los mismos datos.
GRANULARIDAD.
Se refiere a la especificidad a la que se define un nivel de detalle en una tabla, es decir, si hablamos de una jerarquía la granularidad empieza por la parte más alta de la jerarquía, siendo la granularidad mínima, el nivel más bajo.
MODELOS DE CONSISTENCIA.
Es esencialmente un contrato entre procesos y el almacenamiento de datos.
Es decir: si los procesos acuerdan obedecer ciertas reglas, el almacenamiento promete trabajar correctamente.
Normalmente un proceso que realiza una operación de lectura espera que esa operación devuelva un valor que refleje el resultado de la última operación de escritura sobre el dato.
Los modelos de consistencia se presentan divididos en dos conjuntos:
Modelos de consistencia centrados en los datos.
Modelos de consistencia centrados en el cliente.
4.4 MCD en base a variable.
Munin:
Consistencia de liberación.
Protocolos múltiples.
Directorios.
Sincronización.
Midway:
Consistencia de entrada.
Implementación.
La compartición falsa se produce cuando dos procesos se pelean el acceso a la misma página de memoria, ya que contiene variables que requieren los dos, pero estas no son las mismas. Esto pasa por un mal diseño del tamaño de las páginas y por la poca relación existente entre variables de la misma página.
En los MCD basados en variables se busca evitar la compartición falsa ejecutando un programa en cada CPU que se comunica con una central, la que le provee de variables compartidas, administrando este cualquier tipo de variable, poniendo variables grandes en varias páginas o en la misma página muchas variables del mismo tipo, en este protocolo es muy importante declarar las variables compartidas.
En los MCD basados en objetos se busca el acceso a datos por medio de la encapsulación de la información. Y repartida a través de la red, estos objetos serán definidos por el Programador y las CPUs cambiaran los estados según procedan con los accesos.
MCD BASADA EN VARIABLES COMPARTIDAS
El problema del false sharing puede eliminarse si se utiliza una granularidad más tan fin tan fina, como las entidades que usualmente se comparten en los programas paralelos:
Las variables. De ser así, el problema ahora consiste en cómo mantener registro de las variables replicadas. Además, es probable que sea más conveniente utilizar una política de actualización y no de invalidación, puesto que en la implementación debe ser posible identificar escrituras a variables individuales.
4.5 MCD en base a objetos.
Nace como respuesta a la creciente popularización de los lenguajes orientados por objetos.
Los datos se organizan y son transportados en unidades de objetos, no unidades de páginas.
Es un modelo de programación de DSM de alto nivel.
Una alternativa al uso de páginas es tomar el objeto como base de la transferencia de memoria. Aunque el control de la memoria resulta más complejo, el resultado es al mismo tiempo modular y flexible, y la sincronización y el acceso se pueden integrar limpiamente. Otra de las restricciones de este modelo es que todos los accesos a los objetos compartidos han de realizarse mediante llamadas a los métodos de los objetos, con lo que no se admiten programas no modulares y se consideran incompatibles.
Un ejemplo de un sistema de MCD que utiliza una granularidad a nivel de variable compartida es Munin, una de las primeras implementaciones de MCD. Munin permite la ubicación de variables individuales en páginas diferentes, de modo que se pueda utilizar el hardware de paginación para identificar los accesos a las variables compartidas.
domingo, 28 de octubre de 2012
Unidad 3. Procesos y Procesadores en Sistemas Distribuidos.
3.1 Conceptos Básicos.
Un proceso es un concepto manejado por el sistema operativo que consiste en el conjunto formado por: Las instrucciones de un programa destinadas a ser ejecutadas por el microprocesador
Los procesadores distribuidos se pueden organizar de varias formas:
- Modelo de estación de trabajo.
- Modelo de la pila de procesadores.
- Modelo híbrido.
3.2 Métodos de distribución de cargas (Hilos, Tareas, Procesos)
- Threads llamados procesos ligeros o contextos de ejecución.
- Típicamente, cada thread controla un único aspecto dentro de un programa.
- Todos los threads comparten los mismos recursos, al contrario que los procesos en donde cada uno tiene su propia copia de código y datos (separados unos de otros).
Los sistemas operativos generalmente implementan hilos de dos maneras:
Multihilo Apropiativo
Permite al sistema operativo determinar cuándo debe haber un cambio de contexto.
La desventaja de esto es que el sistema puede hacer un cambio de contexto en un momento inadecuado, causando un fenómeno conocido como inversión de prioridades y otros problemas.
Multihilo Cooperativo
Depende del mismo hilo abandonar el control cuando llega a un punto de detención, lo cual puede traer problemas cuando el hilo espera la disponibilidad de un recurso.
3.3 Modelos de Procesadores.
La historia de los microprocesadores comienza en el año 1971, con el desarrollo por parte de Intel del procesador 4004, para facilitar el diseño de una calculadora.
La época de los PC (Personal Computer), podemos decir que comienza en el año 1978, con la salida al mercado del procesador Intel 8086.
Estación de Trabajo.
Los usuarios tienen:
- Una cantidad fija de poder de cómputo exclusiva.
- Un alto grado de autonomía para asignar los recursos de su estación de trabajo.
- Uso de los discos en las estaciones de trabajo:
Sin disco: Bajo costo, fácil mantenimiento del hardware y del software, simetría y flexibilidad.
Con disco: Disco para paginación y archivos de tipo borrador:
Reduce la carga de la red respecto del caso anterior.
Alto costo debido al gran número de discos necesarios.
Modelo de Pila de Procesadores
Este modelo basa su funcionamiento en la teoría de colas.
En general este modelo puede reducir significativamente el tiempo de espera al tener una sola cola de procesadores a repartir.
La capacidad de cómputo se puede gestionar de mejor forma si se tiene micros con mayores capacidades.
Híbrido.
Los sistemas híbridos combinan una variedad de buses de instrumentación y plataformas en un sistema.
Los sistemas híbridos proporcionan una mayor flexibilidad y una longevidad extendida para el sistema de prueba a un menor costo al permitirle combinar software y hardware existente con nuevas tecnologías.
3.4 Asignación de Procesadores.
En dedicar un grupo de procesadores a una aplicación mientras dure esta aplicación, de manera que cada hilo de la aplicación se le asigna un procesador.
Una desventaja es que si un hilo de una aplicación se bloquea en espera de una E/S o por sincronización de otro hilo, el procesador de dicho hilo quedara desocupado: no hay multiprogramación de procesadores.
Modelos y Algoritmos con sus Aspectos de Diseño e Implementación.
Algoritmos deterministas vs. Heurísticos.
-Algoritmos centralizados vs. Distribuidos.
- Algoritmos óptimos vs. Subóptimos.
- Algoritmos locales vs. Globales.
- Algoritmos iniciados por el emisor vs. Iniciados por el receptor.
3.5 Coplanificación.
Toma en cuenta los patrones de comunicación entre los procesos durante la planificación
Cada procesador debe utilizar un algoritmo de planificación Round Robin.
Todos los miembros de un grupo se deben colocar en el mismo N° de espacio de tiempo pero en procesadores distintos.
3.6 Tolerancia a Fallos.
La tolerancia a fallos es un aspecto crítico para aplicaciones a gran escala, ya que aquellas simulaciones que pueden tardar del orden de varios días o semanas para ofrecer resultados deben tener la posibilidad de manejar cierto tipo de fallos del sistema o de alguna tarea de la aplicación.
Por lo general, el termino tolerancia a fallos está asociado al almacenamiento en RAID. Los RAID utilizan la técnica Mirroring (en espejo) que permite la escritura simultánea de los datos en más de un disco del array.
3.7 Sistemas Distribuidos en Tiempo Real.
Características:
1. Se activan por evento o por tiempo.
2. Su comportamiento debe ser predecible.
3. Debe ser tolerante a fallas.
4. La comunicación en los sistemas distribuidos de tiempo real debe de ser de alto desempeño.
Clasificación
Sistema de tiempo real suave: significa que no existe problema si se rebasa un tiempo.
Sistema de tiempo real duro: es aquel en el que un tiempo límite no cumplido puede resultar catastrófico.
2.1 Comunicacion: comunicación con cliente - servidor, comunicación con
llamada a procedimiento remoto, comunicación en grupo, tolerancia a
fallos.
La arquitectura cliente-servidor es un modelo de aplicación
distribuida en el que las tareas se reparten entre los proveedores de
recursos o servicios, llamados servidores, y los demandantes, llamados clientes.
Un cliente realiza peticiones a otro programa, el servidor,
que le da respuesta. Esta idea también se puede aplicar a programas que
se ejecutan sobre una sola computadora, aunque es más ventajosa en un
sistema operativo multiusuario distribuido a través de una red de computadoras.
En esta arquitectura la capacidad de proceso está repartida entre los
clientes y los servidores, aunque son más importantes las ventajas de
tipo organizativo debidas a la centralización de la gestión de la
información y la separación de responsabilidades, lo que facilita y
clarifica el diseño del sistema.
La separación entre cliente y servidor
es una separación de tipo lógico, donde el servidor no se ejecuta
necesariamente sobre una sola máquina ni es necesariamente un sólo
programa. Los tipos específicos de servidores incluyen los servidores web,
los servidores de archivo, los servidores del correo, etc. Mientras que
sus propósitos varían de unos servicios a otros, la arquitectura básica
seguirá siendo la misma.
Las Llamadas a Procedimientos Remotos, o RPC por sus siglas en ingles (Remote Procedure Call), es un protocolo
que permite a un programa de ordenador ejecutar código en otra máquina
remota sin tener que preocuparse por las comunicaciones entre ambos. El
protocolo es un gran avance sobre los sockets
usados hasta el momento. De esta manera el programador no tenía que
estar pendiente de las comunicaciones, estando éstas encapsuladas dentro
de las RPC.
Las RPC son muy utilizadas dentro del cliente-servidor.
Siendo el cliente el que inicia el proceso solicitando al servidor que
ejecute cierto procedimiento o función y enviando éste de vuelta el
resultado de dicha operación al cliente.
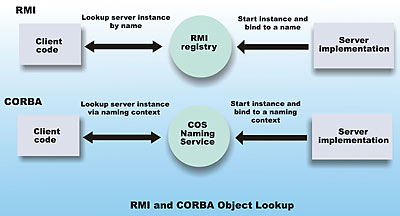
Hay distintos tipos de RPC, muchos de ellos estandarizados como pueden ser el RPC de Sun denominado ONC RPC , el RPC de OSF denominado DCE/RPC, Invocación de Métodos Remotos de Java y el Modelo de Objetos de Componentes Distribuidos de Microsoft DCOM, aunque ninguno de estos es compatible entre sí. La mayoría de ellos utilizan un lenguaje de descripción de interfaz que define los métodos exportados por el servidor.
Hoy en día se está utilizando el XML como lenguaje para definir el IDL y el HTTP como protocolo de red, dando lugar a lo que se conoce como servicios web. Ejemplos de éstos pueden ser SOAP o XML-RPC.
Tolerancias a fallos es a la capacidad de un sistema de almacenamiento de acceder a
información aún en caso de producirse algún fallo. Esta falla puede
deberse a daños físicos (mal funcionamiento) en uno o más componentes de
hardware
lo que produce la pérdida de información almacenada. La tolerancia a
fallos requiere para su implementación que el sistema de almacenamiento
guarde la misma información en más de un componente de hardware o en una
máquina o dispositivo externos a modo de respaldo. De esta forma, si se
produce alguna falla con una consecuente pérdida de datos, el sistema
debe ser capaz de acceder a toda la información recuperando los datos
faltantes desde algún respaldo disponible.
2.2 Sincronización: relojes físicos, relojes lógicos, usos de la sincronización.
Un sistema distribuido debe permitir el apropiado uso de los recursos, debe encargarsede un buen desempeño y de la consistencia de los datos, además de mantener segurastodas estas operacionesLa sincronización de procesos en los sistemas distribuidos resulta más compleja que enlos centralizados, debido a que la información y el procesamiento se mantienen endiferentes nodos.
Un sistema distribuido debe mantener vistas parciales y consistentesde todos los procesos cooperativos y de cómputo. Tales vistas pueden ser provistas por los mecanismos de sincronización.
El término sincronización se define como la forma de forzar un orden parcial o total encualquier conjunto de eventos, y es usado para hacer referencia a tres problemasdistintos pero relacionados entre sí:
1.La sincronización entre el emisor y el receptor.
2.La especificación y control de la actividad común entre procesos cooperativos.
3.La serialización de accesos concurrentes a objetos compartidos por múltiples procesos.
Haciendo referencia a los métodos utilizados en un sistema centralizado, el cual haceuso de semáforos y monitores; en un sistema distribuido se utilizan algoritmosdistribuidos para sincronizar el trabajo común entre los procesos y estos algoritmos
Más informacion y descripciónde los algoritmos:
2.3 Nominación: características y estructuras, tipos de nombres,
resolución y distribución, servidores y agentes de nombre, mapeo de
direcciones, mapeo de rutas, modelo de Terry.
2.4 Comunicación de procesos a través del paso de mensajes en sistemas distribuidos.
1.1 Conceptos y características de los sistemas operativos de redes y sistemas operativos centralizados
Sistema operativo
de red
Sistemas que mantienen a dos o más computadoras
unidas a través de algún medio de comunicación (físico o no), con el objetivo
primordial de poder compartir los diferentes recursos y la información del
sistema.
El primer Sistema Operativo de red estaba enfocado
a equipos con un procesador Motorola 68000, pasando posteriormente a
procesadores Intel como Novell NetWare. Los Sistemas Operativos de red más
ampliamente usados son: Linux, Novell NetWare, Personal NetWare, LAN Manager,
Windows NT Server UNIX.
Una posibilidad es el software débilmente acoplado
en hardware débilmente acoplado Es una solución muy utilizada. Ejemplo
una red de estaciones de trabajo conectadas mediante una LAN. Cada usuario
tiene una estación de trabajo para su uso exclusivo: Tiene su propio S. O. La
mayoría de los requerimientos se resuelven localmente. Es posible que un
usuario se conecte de manera remota con otra estación de trabajo: Mediante un
comando de “login remoto”. Se convierte la propia estación de trabajo del
usuario en una terminal remota enlazada con la máquina remota. Los comandos se
envían a la máquina remota. La salida de la máquina remota se exhibe en la
pantalla local.
Sistema operativo centralizado
Aquel que utiliza los recursos de una sola computadora, es decir, su
memoria, CPU, disco y periféricos. Respecto al hardware podemos decir que se
suele tratar de un computador caro y de gran potencia, con terminales
alfanuméricos directamente conectados. Suele tratarse de una computadora de
tipo desktop, en las cuales es común encontrar un monitor grande con un teclado
y un mouse; además de un case para albergar la unidad de procesamiento y los
demás componentes. Podemos encontrar este tipo de sistemas operativos en un
entorno de empresa, en el cual puede haber un soporte multiusuario.
Las
empresas, en especial las antiguas, utilizan una mainframe potente para dar
capacidad de cómputo a muchos terminales, o también se puede encontrar empresas
con abundantes minicomputadores para los empleados que las necesiten en sus
actividades. Uno de los primeros modelos de ordenadores interconectados fue el
centralizado, donde todo el procesamiento de la organización se llevaba a cabo en una
sola computadora, normalmente un Mainframe, y los usuarios empleaban sencillos
ordenadores personales.
Los problemas de este modelo son que cuando la carga de
procesamiento aumentaba se tenía que cambiar el hardware del Mainframe, lo cual
es más costoso que añadir más computadores personales clientes o servidores que
aumenten las capacidades.
1.2 Conceptos y características de los sistemas operativos distribuidos.
Los sistemas distribuidos están basados en las
ideas básicas de transparencia, eficiencia,
flexibilidad, escalabilidad y fiabilidad. Sin embargo estos
aspectos son en parte contrarios, y por lo tanto los sistemas
distribuidos han de cumplir en su diseño
el compromiso de que todos los puntos anteriores sean
solucionados de manera aceptable.
Transparencia
El concepto de
transparencia de un sistema
distribuido va ligado a la idea de que todo el sistema funcione
de forma similar en todos los puntos de la red,
independientemente de la posición del usuario. Queda como
labor del sistema operativo
el establecer los mecanismos que oculten la naturaleza
distribuida del sistema y que permitan trabajar a los usuarios
como si de un único equipo se tratara.
Eficiencia
La idea base de los sistemas distribuidos es la de
obtener sistemas mucho más rápidos que los
ordenadores actuales. Es en este punto cuando nos encontramos de
nuevo con el paralelismo.
Para lograr un sistema eficiente hay que descartar la
idea de ejecutar un programa en un
único procesador de
todo el sistema, y pensar en distribuir las tareas a los
procesadores libres más rápidos en cada
momento.
La idea de que un procesador vaya a realizar una tarea
de forma rápida es bastante compleja, y depende de muchos
aspectos concretos, como la propia velocidad del
procesador, pero también la localidad del procesador, los
datos, los
dispositivos, etc. Se han de evitar situaciones como enviar un
trabajo de impresión a un ordenador que no tenga conectada
una impresora de
forma local.
Flexibilidad
Un proyecto en
desarrollo
como el diseño
de un sistema operativo distribuido debe estar abierto a cambios
y actualizaciones que mejoren el funcionamiento del sistema. Esta
necesidad ha provocado una diferenciación entre las dos
diferentes arquitecturas del núcleo del sistema operativo:
el núcleo monolítico y el micronúcleo. Las
diferencias entre ambos son los servicios que
ofrece el núcleo del sistema operativo. Mientras el
núcleo monolítico ofrece todas las funciones
básicas del sistema integradas en el núcleo, el
micronúcleo incorpora solamente las fundamentales, que
incluyen únicamente el control de los
procesos y
la
comunicación entre ellos y la memoria. El
resto de servicios se
cargan dinámicamente a partir de servidores en el
nivel de usuario.
Núcleo monolítico
Como ejemplo de sistema operativo de núcleo
monolítico está UNIX. Estos
sistemas tienen un núcleo grande y complejo, que engloba
todos los servicios del sistema. Está programado de forma
no modular, y tiene un rendimiento mayor que un
micronúcleo. Sin embargo, cualquier cambio a
realizar en cualquier servicio
requiere la parada de todo el sistema y la recompilación
del núcleo.
Micronúcleo
La arquitectura de
micronúcleo ofrece la alternativa al núcleo
monolítico. Se basa en una programación altamente modular, y tiene un
tamaño mucho menor que el núcleo monolítico.
Como consecuencia, el refinamiento y el control de errores son
más rápidos y sencillos. Además, la
actualización de los servicios es más sencilla y
ágil, ya que sólo es necesaria la
recompilación del servicio y no
de todo el núcleo. Como contraprestación, el
rendimiento se ve afectado negativamente.
En la actualidad la mayoría de sistemas
operativos distribuidos en desarrollo
tienden a un diseño de micronúcleo. Los
núcleos tienden a contener menos errores y a ser
más fáciles de implementar y de corregir. El
sistema pierde ligeramente en rendimiento, pero a cambio
consigue un gran aumento de la flexibilidad.
Escalabilidad
Un sistema operativo distribuido debería
funcionar tanto para una docena de ordenadores como varios
millares. Igualmente, debería no ser determinante el tipo
de red utilizada (LAN o WAN) ni
las distancias entre los equipos, etc.
La escalabilidad propone que cualquier ordenador
individual ha de ser capaz de trabajar independientemente como un
sistema distribuido, pero también debe poder hacerlo
conectado a muchas otras máquinas.
Fiabilidad Una de las ventajas claras que nos ofrece la idea de
sistema distribuido es que el funcionamiento de todo el sistema
no debe estar ligado a ciertas máquinas de la red, sino
que cualquier equipo pueda suplir a otro en caso de que uno se
estropee o falle.
La forma más evidente de lograr la fiabilidad de
todo el sistema está en la redundancia. La información no debe estar almacenada en un
solo servidor de
archivos, sino
en por lo menos dos máquinas. Mediante la redundancia de
los principales archivos o de
todos evitamos el caso de que el fallo de un servidor bloquee
todo el sistema, al tener una copia idéntica de los
archivos en otro equipo.
Comunicación La comunicación entre procesos en sistemas con
un único procesador se lleva a cabo mediante el uso de
memoria
compartida entre los procesos. En los sistemas distribuidos, al
no haber conexión física entre las
distintas memorias de
los equipos, la
comunicación se realiza mediante la transferencia de
mensajes.
1.3
Ventajas y desventajas contra sistemas operativos centralizados,
sistemas operativos para redes, modelo cliente - servidor, modelo de N
capas, caracteristicas del hardware y caracteristicas del software
(homogéneos y hetogéneos), direccionamiento lógico y físico.
Es el aumento de la disponibilidad y la mejora
del desempeño para la realización de un balance en la carga del trabajo y en la
compartición de recursos compartiendo diferente información y tiene confiabilidad
y disponibilidad a la tolerancia de fallas en la modularidad en el desarrollo
la flexibilidad, crecimiento incremental, reducción de costos y la mayor capacidad
de modelar estructuras organizacionales para determinar la información
basada no debemos de olvidar las desventajas que conlleva un sistema
centralizado como lo son:
Ventajas:
Procesadores más poderosos y a menos costos
Desarrollo de Estaciones con más capacidades
Las estaciones satisfacen las necesidades de los usuarios.
Uso de nuevas interfaces.
Avances en la Tecnología de Comunicaciones.
Disponibilidad de elementos de Comunicación.
Desarrollo de nuevas técnicas.
Compartición de Recursos.
Dispositivos (Hardware).
Programas (Software).
Eficiencia y Flexibilidad.
Respuesta Rápida.
Ejecución Concurrente de procesos (En varias computadoras).
Empleo de técnicas de procesamiento distribuido.
Disponibilidad y Confiabilidad.
Sistema poco propenso a fallas (Si un componente no afecta a la disponibilidad del sistema).
Mayores servicios que elevan la funcionalidad (Monitoreo, Telecontrol, Correo Eléctrico, Etc.).
Crecimiento Modular.
Es inherente al crecimiento.
Inclusión rápida de nuevos recursos.
Los recursos actuales no afectan.
Desventajas:
Requerimientos de mayores controles de procesamiento.
Velocidad de propagación de información (Muy lenta a veces).
Servicios de replicación de datos y servicios con posibilidades de fallas.
Mayores controles de acceso y proceso (Commit).
Administración más compleja.
Costos.
1.4 Sistemas distribuidos de alto rendimiento a bajo costo (clustering) en sistemas operativos de libre distribución.
Un cluster es un conjunto de ordenadores que están conectados entre sí
por medio de una red, para compartir recursos con el objetivo de
realizar tareas y funciones como si fuesen un único ordenador (memoria
distribuida).
Sirve
para cuando queramos realizar tareas que necesiten grandes
requerimientos de memoria y CPU y para ahorrarnos horas de trabajo en
tareas y operaciones. Tipos de Cluster
Hay 3 tipos de cluster:
High Performance o Alto rendimiento.
High Availability o Alta Disponibilidad.
High Reliability o Alta Confiabilidad.
Alto Rendimiento
El objetivo es mejorar el rendimiento, de tiempo o precisión, para la solución de un problema. Este tipo suele estar ligado a solucionar los siguientes problemas:
Cálculos matemáticos
Mejora de gráficos
Compilación de programas
Descifrado de códigos
Rendimiento del sistema operativo
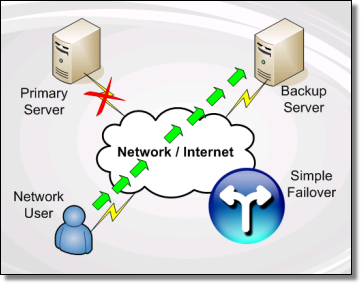
Alta disponibilidad
Los
clusters de alta disponibilidad están destinados a mejorar los
servicios que ofrecen las empresas de cara a los clienrtes de una red,
ya sea local o de internet. Fundamentalmente tienen dos características :
Fiabilidad
Disponibilidad
Alta confiabilidad
Con
alta confiabilidad se trata de aportar la máxima confianza es un
entorno en el cual se necesita saber que el sistema siempre se va a
comportar de una forma determinada, como por ejemplo sistemas de
respuesta a tiempo real. Suele ser usado para entornos de tipo empresarial, necesitando un hardware especializado.
Elementos necesarios
Dos
o más nodos (ordenadores) compuestos al menos por un microprocesador,
una memoia y una interfaz para que se puedan comunicar con la red del
cluster.
Hardware apropiado al tipo de cluster que vamos a utilizar.
Tarjeta de red.
Un medio de transmisión entre ellos como por ejemplo RJ-45.
Software de sistema y un software de aplicación.
Software de sistemaPodemos usar distintos sistemas operatios para conseguir el funcionamiento del cluster, como son:
Ubuntu server
Windows Server
OpenMosix
ParallelKnoppix
Pelican
Software de Aplicación
Dependiendo del sistema operativo que vayamos a utilizar necesitaremos unos paquetes o programas:
En el caso de Linux:
HeartBeat: ejecuta los servicios en los nodos.
HeartBeat-Stonith:
es una técnica HeartBeat que se encarga de controlar que cuando un
servidor esté caído no interfiera en el funcionamiento del cluster.
En el caso del Windows:
A
partir de windows 2003 server los servidores ya viene preparado con el
software necesario. Para mejorar el rendimiento en windows server 2008
podemos usar Failover Cluster.