1.1 Conceptos y características de los sistemas operativos de redes y sistemas operativos centralizados
Sistema operativo
de red
Sistemas que mantienen a dos o más computadoras
unidas a través de algún medio de comunicación (físico o no), con el objetivo
primordial de poder compartir los diferentes recursos y la información del
sistema.
El primer Sistema Operativo de red estaba enfocado
a equipos con un procesador Motorola 68000, pasando posteriormente a
procesadores Intel como Novell NetWare. Los Sistemas Operativos de red más
ampliamente usados son: Linux, Novell NetWare, Personal NetWare, LAN Manager,
Windows NT Server UNIX.
Una posibilidad es el software débilmente acoplado
en hardware débilmente acoplado Es una solución muy utilizada. Ejemplo
una red de estaciones de trabajo conectadas mediante una LAN. Cada usuario
tiene una estación de trabajo para su uso exclusivo: Tiene su propio S. O. La
mayoría de los requerimientos se resuelven localmente. Es posible que un
usuario se conecte de manera remota con otra estación de trabajo: Mediante un
comando de “login remoto”. Se convierte la propia estación de trabajo del
usuario en una terminal remota enlazada con la máquina remota. Los comandos se
envían a la máquina remota. La salida de la máquina remota se exhibe en la
pantalla local.

Sistema operativo centralizado
Aquel que utiliza los recursos de una sola computadora, es decir, su
memoria, CPU, disco y periféricos. Respecto al hardware podemos decir que se
suele tratar de un computador caro y de gran potencia, con terminales
alfanuméricos directamente conectados. Suele tratarse de una computadora de
tipo desktop, en las cuales es común encontrar un monitor grande con un teclado
y un mouse; además de un case para albergar la unidad de procesamiento y los
demás componentes. Podemos encontrar este tipo de sistemas operativos en un
entorno de empresa, en el cual puede haber un soporte multiusuario.
Las
empresas, en especial las antiguas, utilizan una mainframe potente para dar
capacidad de cómputo a muchos terminales, o también se puede encontrar empresas
con abundantes minicomputadores para los empleados que las necesiten en sus
actividades. Uno de los primeros modelos de ordenadores interconectados fue el
centralizado, donde todo el procesamiento de la organización se llevaba a cabo en una
sola computadora, normalmente un Mainframe, y los usuarios empleaban sencillos
ordenadores personales.
Los problemas de este modelo son que cuando la carga de
procesamiento aumentaba se tenía que cambiar el hardware del Mainframe, lo cual
es más costoso que añadir más computadores personales clientes o servidores que
aumenten las capacidades.

1.2 Conceptos y características de los sistemas operativos distribuidos.
Los sistemas distribuidos están basados en las
ideas básicas de transparencia, eficiencia,
flexibilidad, escalabilidad y fiabilidad. Sin embargo estos
aspectos son en parte contrarios, y por lo tanto los sistemas
distribuidos han de cumplir en su diseño
el compromiso de que todos los puntos anteriores sean
solucionados de manera aceptable.
Transparencia
El concepto de
transparencia de un sistema
distribuido va ligado a la idea de que todo el sistema funcione
de forma similar en todos los puntos de la red,
independientemente de la posición del usuario. Queda como
labor del sistema operativo
el establecer los mecanismos que oculten la naturaleza
distribuida del sistema y que permitan trabajar a los usuarios
como si de un único equipo se tratara.
Eficiencia
La idea base de los sistemas distribuidos es la de
obtener sistemas mucho más rápidos que los
ordenadores actuales. Es en este punto cuando nos encontramos de
nuevo con el paralelismo.
Para lograr un sistema eficiente hay que descartar la
idea de ejecutar un programa en un
único procesador de
todo el sistema, y pensar en distribuir las tareas a los
procesadores libres más rápidos en cada
momento.
La idea de que un procesador vaya a realizar una tarea
de forma rápida es bastante compleja, y depende de muchos
aspectos concretos, como la propia velocidad del
procesador, pero también la localidad del procesador, los
datos, los
dispositivos, etc. Se han de evitar situaciones como enviar un
trabajo de impresión a un ordenador que no tenga conectada
una impresora de
forma local.
Flexibilidad
Un proyecto en
desarrollo
como el diseño
de un sistema operativo distribuido debe estar abierto a cambios
y actualizaciones que mejoren el funcionamiento del sistema. Esta
necesidad ha provocado una diferenciación entre las dos
diferentes arquitecturas del núcleo del sistema operativo:
el núcleo monolítico y el micronúcleo. Las
diferencias entre ambos son los servicios que
ofrece el núcleo del sistema operativo. Mientras el
núcleo monolítico ofrece todas las funciones
básicas del sistema integradas en el núcleo, el
micronúcleo incorpora solamente las fundamentales, que
incluyen únicamente el control de los
procesos y
la
comunicación entre ellos y la memoria. El
resto de servicios se
cargan dinámicamente a partir de servidores en el
nivel de usuario.
Núcleo monolítico
Como ejemplo de sistema operativo de núcleo
monolítico está UNIX. Estos
sistemas tienen un núcleo grande y complejo, que engloba
todos los servicios del sistema. Está programado de forma
no modular, y tiene un rendimiento mayor que un
micronúcleo. Sin embargo, cualquier cambio a
realizar en cualquier servicio
requiere la parada de todo el sistema y la recompilación
del núcleo.

Micronúcleo
La arquitectura de
micronúcleo ofrece la alternativa al núcleo
monolítico. Se basa en una programación altamente modular, y tiene un
tamaño mucho menor que el núcleo monolítico.
Como consecuencia, el refinamiento y el control de errores son
más rápidos y sencillos. Además, la
actualización de los servicios es más sencilla y
ágil, ya que sólo es necesaria la
recompilación del servicio y no
de todo el núcleo. Como contraprestación, el
rendimiento se ve afectado negativamente.
En la actualidad la mayoría de sistemas
operativos distribuidos en desarrollo
tienden a un diseño de micronúcleo. Los
núcleos tienden a contener menos errores y a ser
más fáciles de implementar y de corregir. El
sistema pierde ligeramente en rendimiento, pero a cambio
consigue un gran aumento de la flexibilidad.
Escalabilidad
Un sistema operativo distribuido debería
funcionar tanto para una docena de ordenadores como varios
millares. Igualmente, debería no ser determinante el tipo
de red utilizada (LAN o WAN) ni
las distancias entre los equipos, etc.
La escalabilidad propone que cualquier ordenador
individual ha de ser capaz de trabajar independientemente como un
sistema distribuido, pero también debe poder hacerlo
conectado a muchas otras máquinas.
Fiabilidad
Una de las ventajas claras que nos ofrece la idea de
sistema distribuido es que el funcionamiento de todo el sistema
no debe estar ligado a ciertas máquinas de la red, sino
que cualquier equipo pueda suplir a otro en caso de que uno se
estropee o falle.
La forma más evidente de lograr la fiabilidad de
todo el sistema está en la redundancia. La información no debe estar almacenada en un
solo servidor de
archivos, sino
en por lo menos dos máquinas. Mediante la redundancia de
los principales archivos o de
todos evitamos el caso de que el fallo de un servidor bloquee
todo el sistema, al tener una copia idéntica de los
archivos en otro equipo.
Comunicación
La comunicación entre procesos en sistemas con
un único procesador se lleva a cabo mediante el uso de
memoria
compartida entre los procesos. En los sistemas distribuidos, al
no haber conexión física entre las
distintas memorias de
los equipos, la
comunicación se realiza mediante la transferencia de
mensajes.
1.3
Ventajas y desventajas contra sistemas operativos centralizados,
sistemas operativos para redes, modelo cliente - servidor, modelo de N
capas, caracteristicas del hardware y caracteristicas del software
(homogéneos y hetogéneos), direccionamiento lógico y físico.
Es el aumento de la disponibilidad y la mejora
del desempeño para la realización de un balance en la carga del trabajo y en la
compartición de recursos compartiendo diferente información y tiene confiabilidad
y disponibilidad a la tolerancia de fallas en la modularidad en el desarrollo
la flexibilidad, crecimiento incremental, reducción de costos y la mayor capacidad
de modelar estructuras organizacionales para determinar la información
basada no debemos de olvidar las desventajas que conlleva un sistema
centralizado como lo son:
Ventajas:
- Procesadores más poderosos y a menos costos
- Desarrollo de Estaciones con más capacidades
- Las estaciones satisfacen las necesidades de los usuarios.
- Uso de nuevas interfaces.
- Avances en la Tecnología de Comunicaciones.
- Disponibilidad de elementos de Comunicación.
- Desarrollo de nuevas técnicas.
- Compartición de Recursos.
- Dispositivos (Hardware).
- Programas (Software).
- Eficiencia y Flexibilidad.
- Respuesta Rápida.
- Ejecución Concurrente de procesos (En varias computadoras).
- Empleo de técnicas de procesamiento distribuido.
- Disponibilidad y Confiabilidad.
- Sistema poco propenso a fallas (Si un componente no afecta a la disponibilidad del sistema).
- Mayores servicios que elevan la funcionalidad (Monitoreo, Telecontrol, Correo Eléctrico, Etc.).
- Crecimiento Modular.
- Es inherente al crecimiento.
- Inclusión rápida de nuevos recursos.
- Los recursos actuales no afectan.
 Desventajas:
Desventajas:
- Requerimientos de mayores controles de procesamiento.
- Velocidad de propagación de información (Muy lenta a veces).
- Servicios de replicación de datos y servicios con posibilidades de fallas.
- Mayores controles de acceso y proceso (Commit).
- Administración más compleja.
- Costos.
1.4 Sistemas distribuidos de alto rendimiento a bajo costo (clustering) en sistemas operativos de libre distribución.
Un cluster es un conjunto de ordenadores que están conectados entre sí
por medio de una red, para compartir recursos con el objetivo de
realizar tareas y funciones como si fuesen un único ordenador (memoria
distribuida).

Sirve
para cuando queramos realizar tareas que necesiten grandes
requerimientos de memoria y CPU y para ahorrarnos horas de trabajo en
tareas y operaciones.
Tipos de Cluster
Hay 3 tipos de cluster:
- High Performance o Alto rendimiento.
- High Availability o Alta Disponibilidad.
- High Reliability o Alta Confiabilidad.
Alto Rendimiento
El objetivo es mejorar el rendimiento, de tiempo o precisión, para la solución de un problema.
Este tipo suele estar ligado a solucionar los siguientes problemas:
- Cálculos matemáticos
- Mejora de gráficos
- Compilación de programas
- Descifrado de códigos
- Rendimiento del sistema operativo
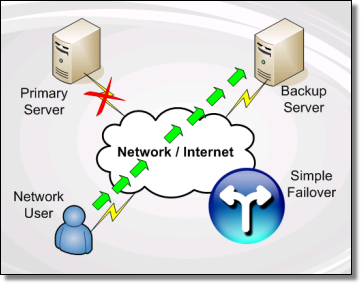
Alta disponibilidad
Los
clusters de alta disponibilidad están destinados a mejorar los
servicios que ofrecen las empresas de cara a los clienrtes de una red,
ya sea local o de internet. Fundamentalmente tienen dos características :
- Fiabilidad
- Disponibilidad
Alta confiabilidad
Con
alta confiabilidad se trata de aportar la máxima confianza es un
entorno en el cual se necesita saber que el sistema siempre se va a
comportar de una forma determinada, como por ejemplo sistemas de
respuesta a tiempo real.
Suele ser usado para entornos de tipo empresarial, necesitando un hardware especializado.

Elementos necesarios
- Dos
o más nodos (ordenadores) compuestos al menos por un microprocesador,
una memoia y una interfaz para que se puedan comunicar con la red del
cluster.
- Hardware apropiado al tipo de cluster que vamos a utilizar.
- Tarjeta de red.
- Un medio de transmisión entre ellos como por ejemplo RJ-45.
- Software de sistema y un software de aplicación.
Software de sistemaPodemos usar distintos sistemas operatios para conseguir el funcionamiento del cluster, como son:
- Ubuntu server
- Windows Server
- OpenMosix
- ParallelKnoppix
- Pelican
Software de Aplicación
Dependiendo del sistema operativo que vayamos a utilizar necesitaremos unos paquetes o programas:
En el caso de Linux:
- HeartBeat: ejecuta los servicios en los nodos.
- HeartBeat-Stonith:
es una técnica HeartBeat que se encarga de controlar que cuando un
servidor esté caído no interfiera en el funcionamiento del cluster.
En el caso del Windows:
- A
partir de windows 2003 server los servidores ya viene preparado con el
software necesario. Para mejorar el rendimiento en windows server 2008
podemos usar Failover Cluster.